Every Book in Pathway has its own AI agent, Jack. It runs in a Linux sandbox with Python, a filesystem, and network access, and it works with your data using your exact permissions. This page explains how it works, from the context it starts with to the loop it runs.
Using the chat
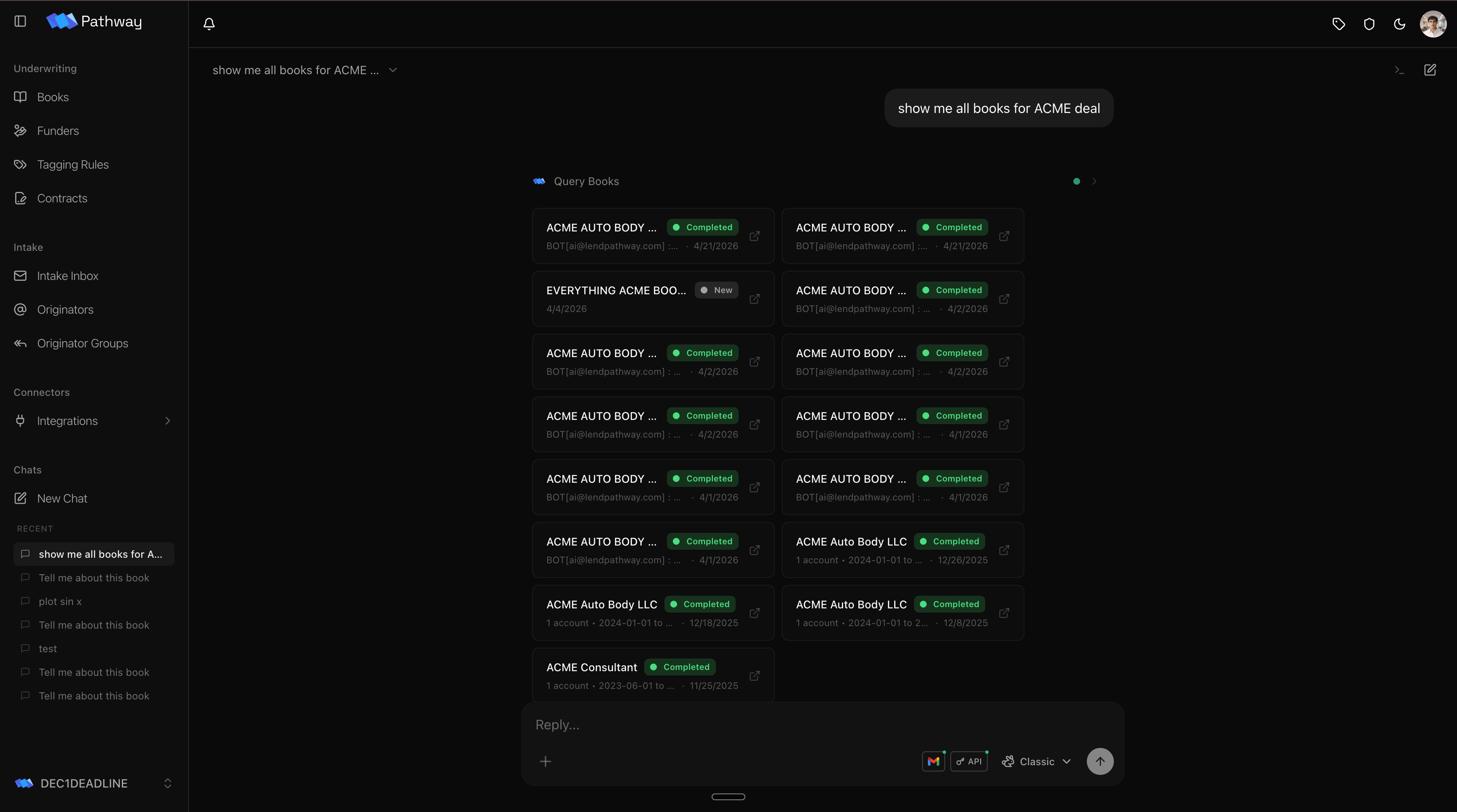
Open a new chat or any existing one. Three controls sit around the composer: what the agent can reach, which model runs it, and how to find past chats.Connectors
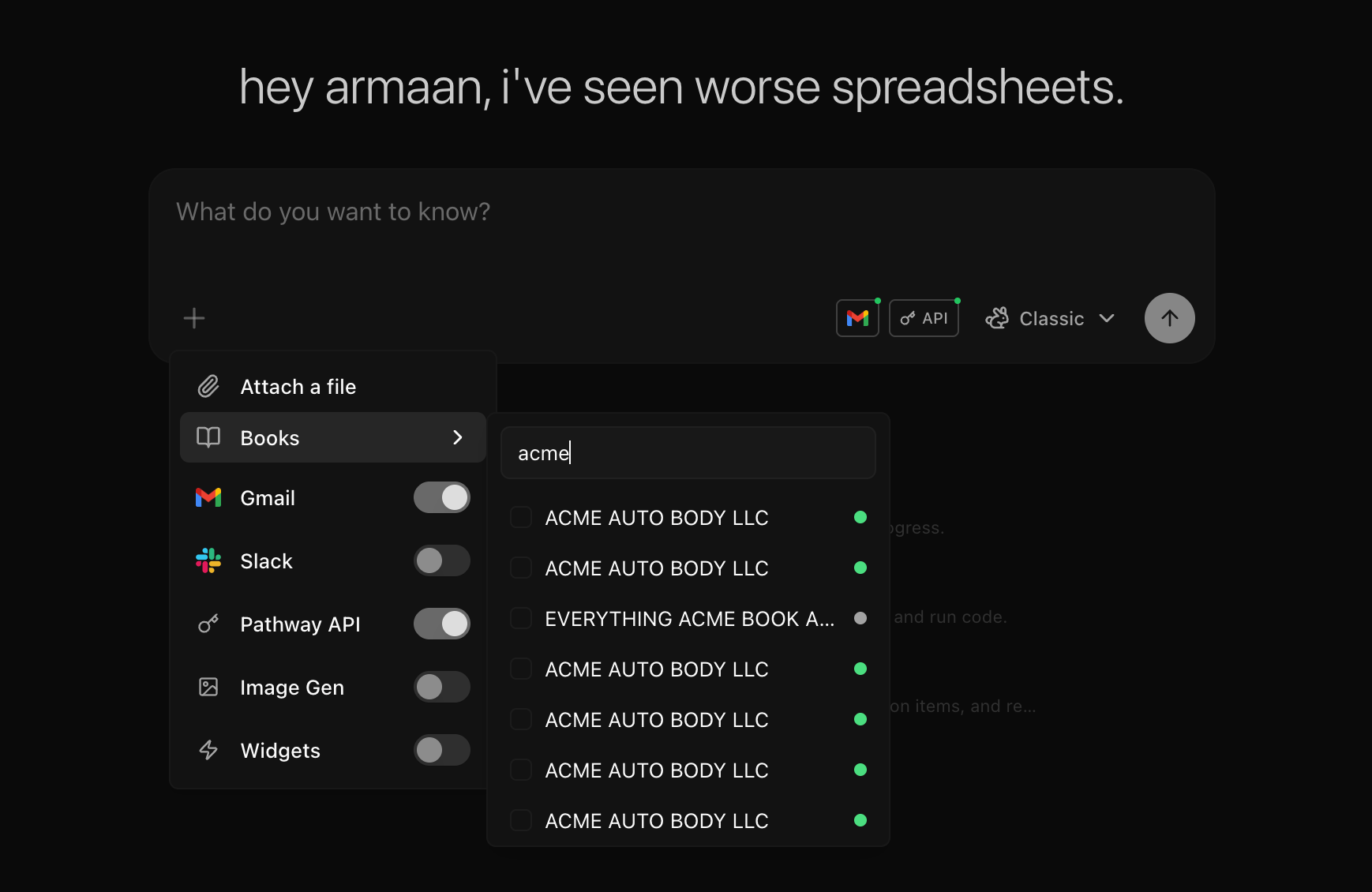
The + button opens the connector menu. Each toggle grants the agent one capability for this chat, and grants are per chat, so the same agent can be wired differently each time. Flip on Books and it can read your deals; add Gmail and it can read your inbox; add the Pathway API and it can query across everything you can access. Turning a connector on does two things: it hands the agent the tools for that surface and adds the instructions for using it to the agent’s context. Keep the set tight. The agent works best when it carries only what the task needs.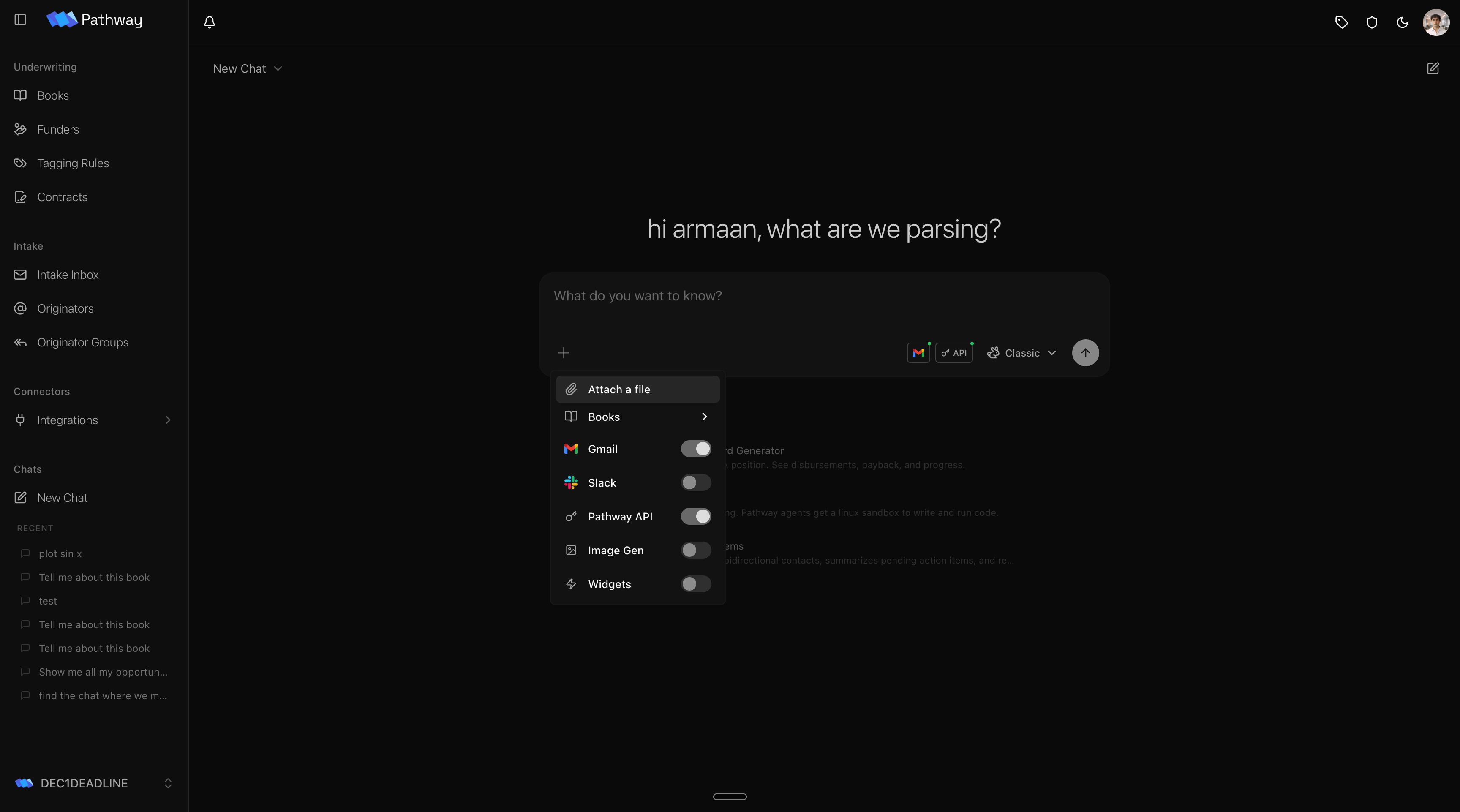
| Toggle | What it gives the agent |
|---|---|
| Attach a file | Upload a CSV, PDF, image, or spreadsheet into the chat for the agent to read |
| Books | Scope the chat to one or more Books so the agent reads their parsed data and analytics |
| Gmail | Read the connected inbox through the read-only proxy, plus the approval-gated send_email tool |
| Slack | Post messages to the org’s connected Slack channels |
| Pathway API | The read-only platform API: query Books, documents, analytics, funders, and more across what the user can access |
| Image Gen | Generate images from a prompt |
| Widgets | Render interactive UI back into the chat |
Connectors map directly to the context the agent receives. Each one you enable appends its instructions to the system prompt, which is why a focused set of toggles keeps the agent sharp. See What the model sees.
Chatting about a Book
Open a chat from inside a Book and that Book is attached automatically. The agent starts scoped to the deal in front of you, so you can ask about it right away.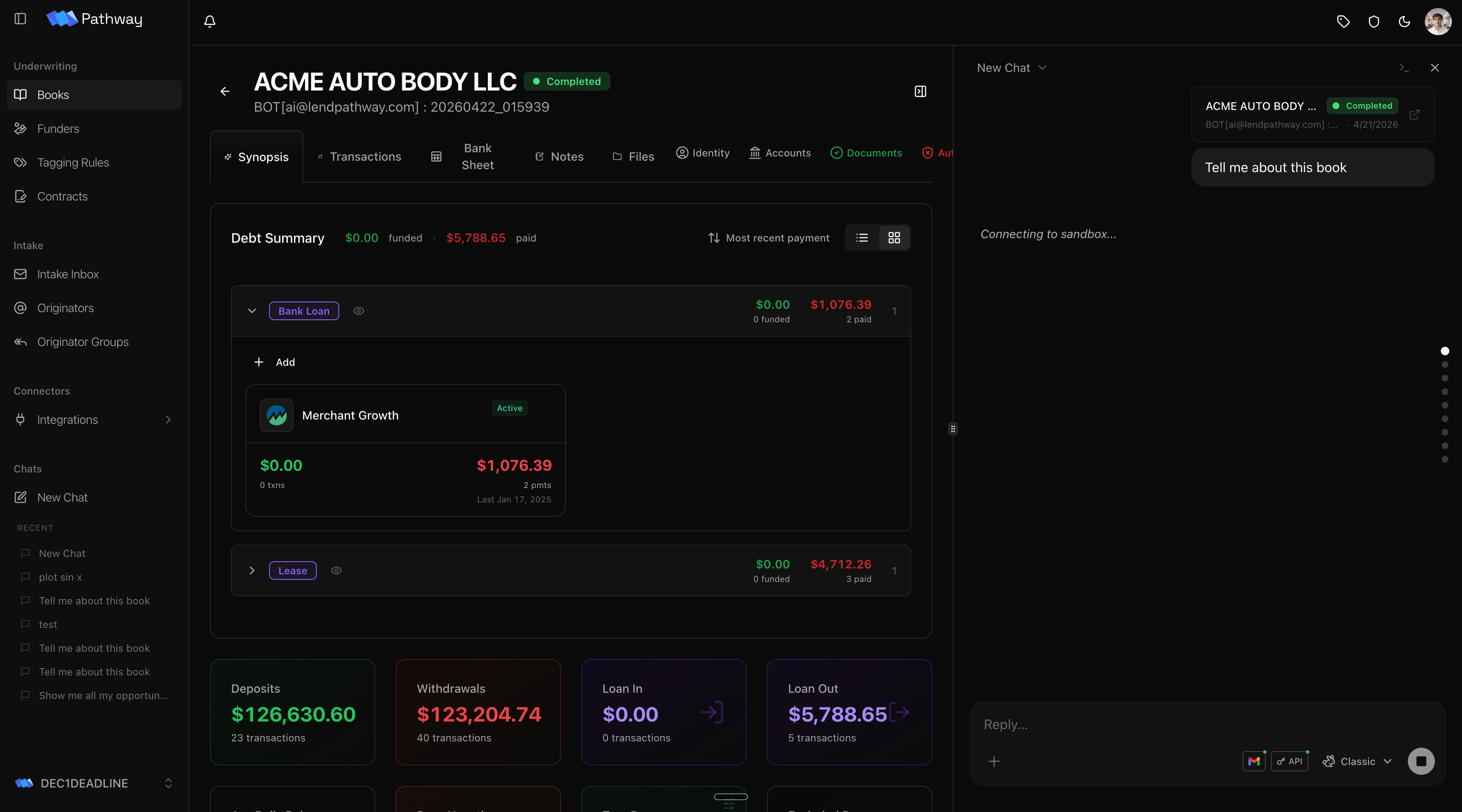
Inline
@ references to pull a Book into the middle of a message are coming soon.Model
The model selector sets which model runs the chat. Pathway runs the agent on Gemini across the board, by choice, and exposes the current lineup as three tiers.
| Tier | Model | Use it for |
|---|---|---|
| Lightning | Gemini 3.1 Flash-Lite | Fast, lightweight questions and quick edits |
| Classic | Gemini 3.5 Flash | The default balance of speed and depth |
| Pro | Gemini 3.1 Pro | The hardest reasoning and multi-step analysis |
Find past chats
Open the New Chat dropdown to search and reopen earlier chats. The search box filters your history by title.
What you can do
Ask about a Book
Total deposits, true revenue, debt-to-income, a single transaction, a counterparty breakdown. The agent computes from the source data, not from a summary.
Build charts and reports
Ask for a revenue trend, a cash flow heatmap, a custom Excel export, or an HTML report. The output renders inline in the chat.
Work with email
Connect Gmail and the agent can search the inbox, read threads, download attachments, and compare them against Book data. Sending requires your approval.
Attach files
Drop in a CSV, PDF, image, or spreadsheet. The agent reads it, parses it, and cross-references it against the Book.
Chats don’t have to be attached to a Book. A standalone chat gets the same sandbox and tools, just without a Book to read from. Use them for general computation or analysis.
How it works
Three pieces make up the engine.Scoped access
The agent reads only what the current user can read. Its permissions are the user’s permissions.
What the model sees
Before any tool runs, the backend assembles the context for the turn. It is built fresh each time, in a fixed order.Preamble
The current date and time, and a line identifying the user and org by name and ID. This grounds the agent in who it is acting for.
Base instructions
The core system prompt: how to use the sandbox, the tool conventions, and the rules for sharing files and computing instead of guessing.
Skills index
One line per skill, name and description. The full text is pulled on demand with
read_skill.Capability sections
A section is appended for each capability the chat has enabled. Each one teaches the agent how to use that surface.
| Capability | What gets injected |
|---|---|
| Pathway API | The full read-only API reference: how to read the token, list and filter Books, fetch book_meta and analytics, pull documents, and follow provenance back to an email thread or CRM record |
| Gmail | The read-only Gmail proxy, its endpoints, and Gmail search syntax, plus the approval-gated send_email tool |
| Salesforce | How to run read-only SOQL with query_salesforce and page large results into the sandbox with export_salesforce_to_sandbox |
| Slack | The connected channels and the post_to_slack block format |
| Image generation | The generate_image tool |
| Widgets | How to render interactive UI back into the chat |
The whole assembled prompt is sent as the first message of the turn, followed by the conversation history. The agent reads live data through the injected APIs rather than from a frozen snapshot, so it always works against the current state of a Book.
The sandbox
Each chat gets a fresh sandbox, created from a cached snapshot in seconds. It runs Amazon Linux with Python 3.13 and fullsudo. pandas, numpy, matplotlib, seaborn, openpyxl, xlsxwriter, scipy, tabulate, duckdb, streamlit, and plotly are pre-installed. Anything else installs with pip, and system packages install with dnf. The filesystem is rooted at /tmp/, and the network is open.
Two things are placed in the sandbox before the first message:
| Path | Contents |
|---|---|
/tmp/.api_token | A read-only API token for the current user. The agent uses it to call Pathway APIs and the Gmail proxy |
/tmp/uploads/ | Files the user attached to the conversation |
/tmp/. Book data is not dumped to disk up front. The agent reads it live through the API when it needs it, which keeps the workspace small and the data current.
Sandboxes are ephemeral. They live for the conversation and are destroyed after. If one times out mid-conversation, a new one is created from the snapshot, the token and uploads are restored, and the conversation continues.
The first sandbox on the platform bootstraps the package set and takes a snapshot. The snapshot is cached in Redis with a 29-day TTL and refreshed before it expires, so every later sandbox starts from it.
The filesystem is the memory
The agent does not pass data between steps through a message protocol. It writes files and reads them back. The filesystem is its working memory. It pulls a Book’s analytics from the API and saves the response to a file. It downloads a document and opens it withview. It writes an intermediate result and finds it again later with ls, cat, grep, or a script. State that matters is on disk, not held in the prompt.
This is why cross-domain work needs no special integration. Asked to compare bank deposits against invoices from email, the agent:
Pulls the invoices
Calls the Gmail proxy to find the thread, then downloads the attachments to the sandbox.
Tools
The core tools are built on two primitives: the shell and the filesystem.bash — run any shell command
bash — run any shell command
The primary tool. Runs scripts, installs packages with
pip or dnf, calls endpoints with curl, pipes output. stdout and stderr come back as text. Long output is truncated at the midpoint to keep the context window manageable.write — create or overwrite a file
write — create or overwrite a file
Writes content to a path, creating parent directories as needed. For Python scripts the agent usually writes through a
bash heredoc instead, which keeps the script and its run in one step.edit — exact string replacement
edit — exact string replacement
Replaces a known string in an existing file. Used to revise a script or file in place after the agent has read it.
view — read a file
view — read a file
Reads a file. Text comes back with line numbers. Images and PDFs are rendered into the model’s visual context, so the agent can actually see them.
save_artifact — publish a file to the chat
save_artifact — publish a file to the chat
Reads a file from the sandbox, uploads it to permanent storage, and returns a URL through the asset proxy. The agent embeds the URL in its response. Images render inline, HTML in a sandboxed iframe, Excel as a live Office Online preview, everything else as a download link.
save_artifact is for the user: a permanent URL rendered in the response. view is for the agent: bytes in the context window for visual reasoning.
That second one closes the loop. The agent can write a script, generate a chart or spreadsheet, view the result, fix the script, and run it again before it ever responds.
Skills
A skill is a written set of instructions for a task the agent does often: generating a PDF with Typst, extracting tables from a scanned statement, publishing an interactive dashboard, doing web research. Skills keep the agent reliable on hard tasks without bloating its context. Each skill appears in the system prompt as a single line: a name and a short description. The full instructions stay out of context until the agent decides it needs them, then it loads them withread_skill.
Extending the agent with code
The agent does not need a custom plugin for every system. It has a real computer, so reaching something new is usually just code.- Any API: the agent can
curlan endpoint orpip installa client and call it from Python. Anything with an HTTP interface, including MCP servers, is reachable from the sandbox. - Reusable instructions: drop a Markdown file or a Python snippet into the Book, and the agent reads it like any other file. A documented procedure becomes something the agent can follow; a helper script becomes something it can run.
- New packages and tools:
pip installfor Python,sudo dnf installfor system packages. If a task needs a library that isn’t preinstalled, the agent installs it.
Scoped platform access
Every chat carries a temporary, read-only API token for the current user, written to/tmp/.api_token. It lets the agent call Pathway’s own APIs under the user’s access control: Books, documents, analytics, funders, screening settings, emails, and organization data. The Gmail proxy uses the same token.
This is how the agent reasons across many Books without loading the whole organization into the prompt. It finds the Books it needs with the query_books tool, fetches analytics for the relevant ones from the API, and runs Python over what it is allowed to read.
Gmail
When a user connects Gmail, the agent reads the inbox through a read-only proxy at/api/google-inbox/proxy/, using the same API token. The proxy only accepts GET requests, so reading is read-only by design. Any Gmail read endpoint works through it: search messages, fetch a message or thread, list labels, download an attachment.
pandas, a PDF gets inspected with view, an invoice image gets read visually by the model.
Sending is the one exception. It runs through the send_email tool, which composes a message and attaches sandbox files, and the user must approve it before it goes out.
Book data
A Book chat is pointed at a Book, and the agent reads that Book’s data from the Pathway API. Two endpoints carry most of it.- Raw parser output
- Computed analytics
GET /api/books/{id} returns the Book including book_meta: business identity, owner details, bank account metadata, ledger transactions with dates and descriptions, loan positions with matched disbursements and payment schedules, web research, and tampering analysis.The parser owns the structured Book. The agent works on top of it. It does not replace deterministic parsing, reconciliation, or analytics. It gives you a way to ask new questions and produce new artifacts without waiting for a new product workflow.
Artifacts and the asset proxy
Every file in the platform lives in S3 and is served through one endpoint:/api/assets/{s3_key}. The key holds an unguessable UUID, so the endpoint needs no separate login. It signs a short-lived URL and returns a redirect.
The frontend receives a URL, checks the mime type, and renders the matching preview: images inline, PDFs in a viewer, HTML in a sandboxed iframe, Excel in Office Online, everything else as a download link. It does not distinguish between a chart the agent just made and a spreadsheet the parser produced. Both are just files behind the same proxy.
For Excel files, adding
?embed=office returns a fresh Office Online embed URL instead of a redirect. This powers the interactive spreadsheet previews in chat, in the Book’s spreadsheet tab, and in the embed API.State
Two things hold the state of a chat: the sandbox filesystem and the conversation history. Files on disk, messages in the database. That is the whole system. A shell, a filesystem, and two additions on top:save_artifact to publish a file, and view to let the agent see one. Simple primitives that compose into the work.